Early Warning of Conflict in Southern Lebanon using Hidden Markov Models
Philip A. Schrodt
Department of Political Science
Penn State University
Paper presented at the
American Political Science Association meetings
Washington, DC
August 1997
ABSTRACT
This paper extends earlier work on the use of hidden Markov models (HMMs) to the problem of forecasting international conflict. HMMs are a sequence comparison method that is widely used in computerized speech recognition; they are easily be adapted to work with sequences of international event data. The HMM is a computationally efficient method of generalizing a set of example sequences observed in a noisy environment. The paper provides a theoretical "micro- foundation" for the sequence comparison approach based on co- adaptation of standard operating procedures.
The left-right (LR) HMM used in speech recognition problems is first extended to a left-right-left (LRL) model that allows a crisis to escalate and de-escalate. This model is tested for its ability to correctly discriminate between BCOW crisis that do and do not involve war. The LRL model provides slightly more accurate classification than the LR model. The interpretation of the hidden states in the LRL models, however, is more ambiguous than found in the LR model.
The HMM is then applied to the problem of forecasting the outbreak of armed violence between Israel and Arab forces in south Lebanon during the period 1979 to 1997 (excluding 1982-1985). An HMM first is estimated using six cases of "tit-for-tat" escalation, then fitted to the entire time period. The model identifies about half of the TFT conflictsÑincluding all of the training casesÑthat occur in the full sequence, with only one false positive. This result suggests that HMMs could be used in an event-driven continuous monitoring system. However, the fit of the model is very sensitive to the number of nonevents found in a sequence, and consequently that measure is ineffective as an early warning indicator.
In a subset of models the maximum likelihood estimate of the sequence of hidden Markov states characterizing a sequence provides a robust early warning indicator with a three to six-month lead. These models are valid in a split- sample test, and the patterns of cross-correlation of the individual states of the model are consistent with the theoretical expectations. While this approach clearly needs further validation, it appears promising.
The paper concludes with observations on the extent to which the HMM approach to be generalized to various categories of conflict, some suggestions on how the method of estimation can be improved, and the implications that sequence-based forecasting techniques have for the theoretical understanding of the causes of conflict.
Supplementary Graphics Directory:
Under construction!: additional graphs will be added in the near future...
- Monte Carlo Distribution of Cross-correlations
- Cross-correlations of individual states
- Cross-correlations in the random data
- KEDS Home Page
Monte Carlo Distribution of Cross-correlations
Remarks: Distribution of cross-correlations; 512 Monte Carlo
experiments. X-axis is the cross-correlation; Y-axis is the lag/lead (negative
= warning variable correlates with later values of indicator variable).
Indicator variable was TFT. Color corresponds to the number of experiments
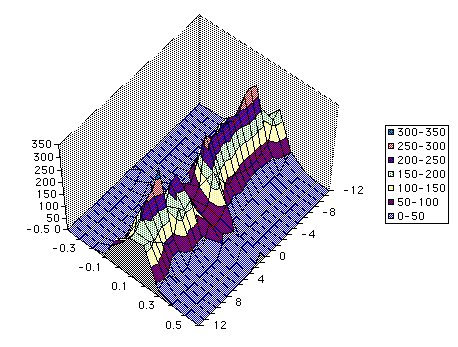
with each value; horizontal dimension sums to 512 for each lag/lead. Remarks: Distribution of cross-correlations; 512 Monte Carlo
experiments. Same as above except for a three-dimensional view. Note the
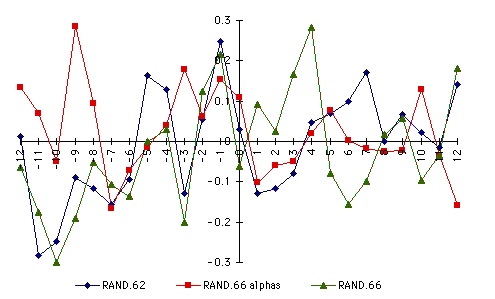
slight dip in the r=0 ridge around lag -4. Remarks: Cross-correlations of the P77 model
for the second half of the data first. This graph combines state A & B,
C & D, E & F
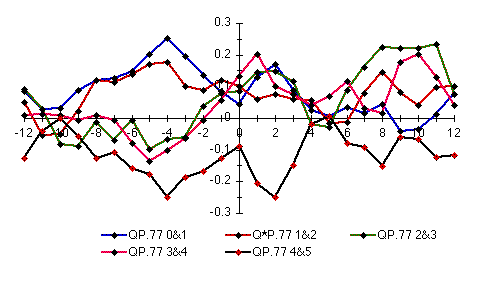
Remarks: Cross-correlations of the P77 model
for the second half of the data in the split-sample test. This graph does
six pairs of states individually
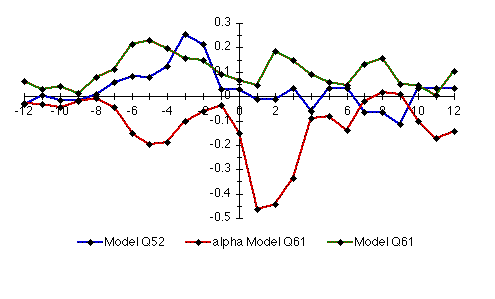
Remarks: Cross-correlations for the Q52
and Q61 models; same as Figure nn except in color Remarks: Cross-correlations for the model
of the random data, second half of the data set. 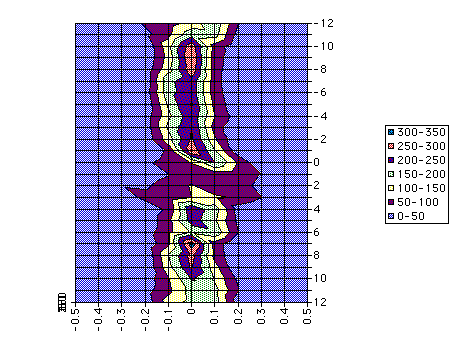
Cross-correlations of individual states
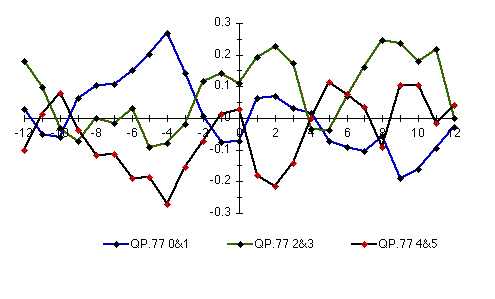
Cross-correlations in the random data